GIT Basics Explained: A Beginner's Perspective
A Guided Walk Through, For Absolute Beginners

My articles on various topics from "Computer Science Basics" to "Software Engineering", "System Design" in beginner-friendly way.
Written with the focus to help my readers to build mental models, real-world analogies, and simple explanations for complex problems.
Introduction
As we embark on our long and arduous journey of learning to code and build complex softwares that can solve real-world problems, the first inevitable bump that we come across is learning Git, the “version control software“ for all the codes and other important files, used in a project.
Hi! my name is Abhirup Roy, I love to build softwares and write about them, and today, in this article, we are going to understand how to use Git, enough to get going. We can always dive deeper later, to master our understanding of the software, from its internal architectures to design strategy and principles used in implementation, and discuss all the mostly used functionalities that Git provides us. But before we can dive that deep, today, in thing article, we will learn how to at least start using Git to track our code changes, like how “pro” engineers do in their production software projects.
Before explaining the “how” part, Let’s have an overview idea about “what is Git?” and '“why should we use git?”
What is Git
In one word over-simplification, Git is the “Undo“ option for software developers!
Like any other projects, a software project is an implementation of an answer to a real-world problem. When we create such a software project, it is obvious, that we need to write many lines of code, often segregated in different files, to keep the design clean, understandable, maintainable and upgradable.
While we do so, we create many files, edit many files, sometime even remove few files to reach to the final version of our solution of the problem. It is quite understandable that, this cannot be done in a single attempt, or most often, not by a single software programmer. Thus, we need an efficient way to track changes in our project files and also provide a mechanism to enable multiple programmers to contribute their progress to the project code base to reach the final implementation of solution. Git does that for us. It is a “distributed version control system“ software. Let’s dissolve the jargons, “version control system” means, it keeps a track onto each programmer’s code changes along with timestamp onto their workstations, and, “distributed“ refers to the ability of Git to allow programmers to submit their delta progress to a central source code storage of project (which is often a remote server), documenting it with an ID, a description, contributor’s name or email and timestamp of contribution.
Why should we use Git
As we got a bird view idea around what is the purpose of Git version control software, let’s also skim through why should we use Git, or any VCS (version control system) software for the matter.
Git is used to track, manage and co-ordinate changes in software project files (i.e. codes and other files) efficiently, when a team of software engineers are working on the same project.
Complete change history tracking by recording author, timestamp and commit message
Easy rollback and debugging in case of errors introduced
Each repository or in short repo, is a full backup of the project, containing all files. Thus, multiple software developers can work on the same repo simultaneously, by working offline and upload their delta change to the repository. In most of the real-world scenarios, we software developers use a remote repository in online platforms like GitHub, BitBucket or GitLab, so that we do not have a single point of failure
Creating branches in Git for experimenting some new risky or experimental changes without jeopardizing entire project’s progress. Creating branches in git is lightweight and fast, enabling developers to develop new features, fix bugs and experiment in their codes. Merging these back to the original main or master branch is also reliable and traceable
If you want to dive deeper and understand why version control system(VCS) softwares exist in the first place and how VCS has evolved from a local change tracking tool to modern day distributed VCS - “Git”, you can read my another article - Why version control exists?
How to Install Git onto your system
Check if Git is installed -
Open a terminal for Linux or Mac OS, a command prompt/PowerShell/GitBash window, depending upon your OS.
Run a command
git --version, if Git is installed onto your system already, you will see Git version information onto your terminal/command prompt.
If Git is not already installed onto your system, you will get a prompt response like
command not foundor‘git’ is not recognized as an internal or external command
Install Git -
Installing Git on Linux -
For Debian based Linux distribution such as Ubuntu -
Updates the package list using
sudo apt updateInstalls git -
sudo apt install git -yverify installation
git --version
For Fedora, CentOS or RHEL -
sudo dnf install git -ygit --version
For Arch Linux -
sudo pacman -S gitgit --version
For OpenSUSE -
sudo zypper install gitgit --version
Installing on MacOS -
Check if homebrew is available on your Mac -
brew --versionInstall homebrew if the above command does not show you homebrew version -
/bin/bash -c "$(curl -fsSLhttps://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"Once the brew installation is comeplete and you get to see brew version information on
brew --versioncommand, install git using following commandbrew install gitgit --versionIf the above method seems complex to you, you can also install git from GUI installer package. For that. follow below steps -
Go to: git-scm.com
Download macOS installer
Run
.pkgfileFollow installation steps
Verify with:
git --version
Installing on Windows -
On Windows OS, Git installation is GUI based and easy. Follow below steps -
Visit: git-scm.com
Click Download for Windows
.exefile will be downloaded to your systemDuring installation -
Keep the default/recommended options/settings
Make sure to select the option on GUI screen, that says - “Git from the command line and also from 3rd-party software”
This ensures that Git will work on command prompt, PowerShell and editors or IDE like VS Code or IntelliJ
After installation, open Command Prompt or PowerShell and run:
git --version
After installing Git onto your system for the first time, you will need to configure your identity in git -
git config --global user.name “Your Name/Name that you want to use in your commit signatures“git config --global user.email “Your email - your.email@example.com“Once they are configured, you can always see them by running
git config --global --listcommand
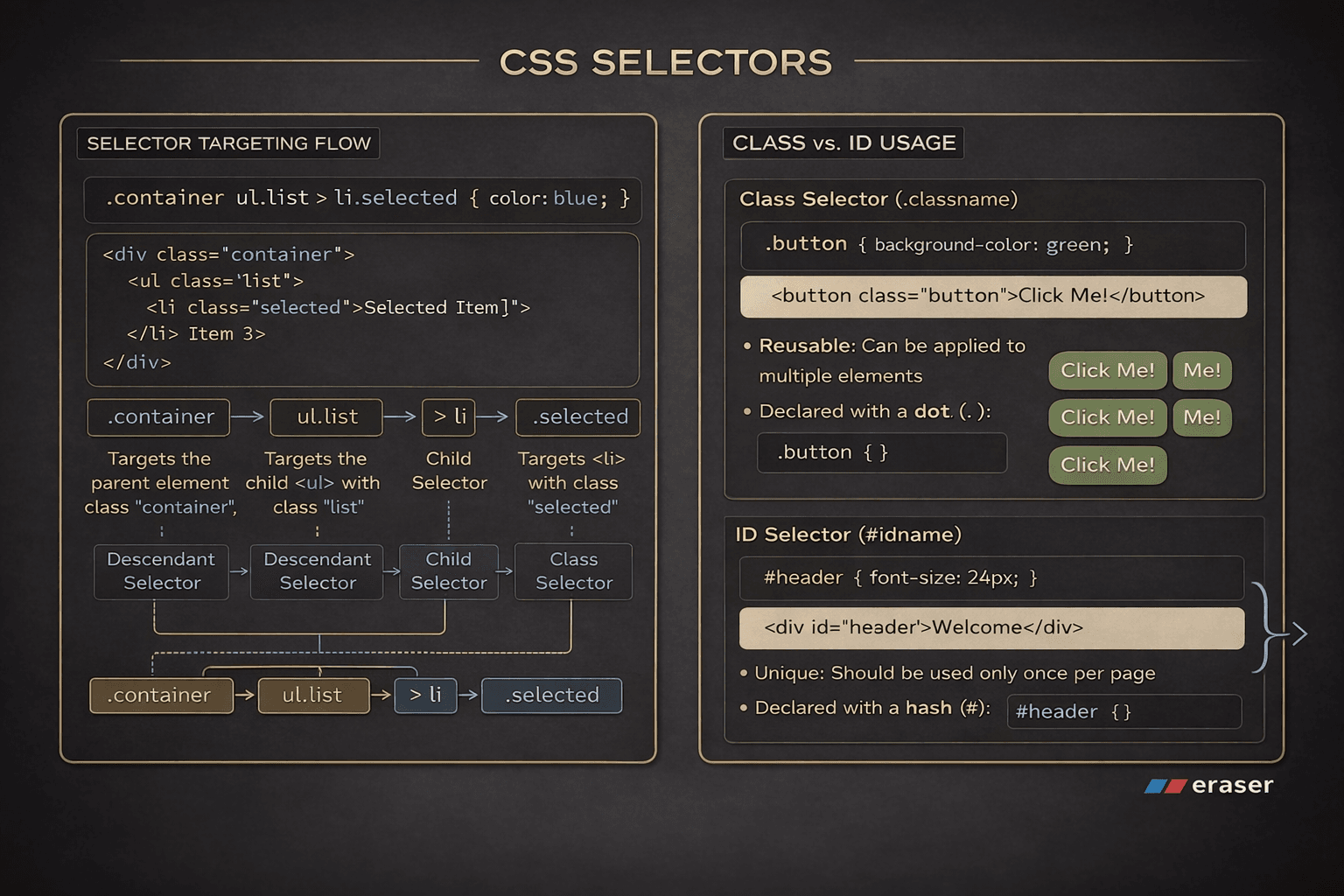
Core Terminologies and Concepts
Think of Git as three zones or areas: Working directory (your files), Staging area (prepare changes) and Repository or repo (saved history).

Working Directory: Current files you edit
Staging Area:
git addmoves changes here for reviewRepository: A repository or simply ‘repo‘ is a Git-managed project.
It contains:
Your project files
Full history of changes
Git metadata inside
.gitfolder
Types of repo:
Local repo → On your computer
remote repo → on GitHub/GitLab/BitBucket etc
Commit: A commit is a snapshot of your project at a point in time created by command
git commit -m "Message". You can think of commit as “Save game checkpoint“. Each commit has:Unique ID (hash created using SHA-1 encryption algorithm)
Author
Timestamp
Message (why the change was made)
Branch: A branch is an independent line of development.
mainormasteris the default branchFeature branches allow safe experimentation
Example - Trying to implementing login feature, onto feature branch, while, main branch is unchanged.

Head: Head tells Git -”This is where I am right now”. Head is a pointer to -
The current branch
The latest commit you’re working on
Git Managed Project Structure
Below is a tree-like representation of a simple, git-managed JavaScript based application project structure, for ease of understanding.

.git/→ Git’s brain. Do not manually make any change to this directory, if you do not wish to unknowingly corrupt your project repo snapshots.File outside
.git/→ Is your actual project. In the above diagram,src/andREADME.mdare your project files, while content inside.git/is not.
Common Git Commands
Initialize a repo: Start in an empty project folder. Open terminal there. Initialize a Git repository using the command :
git init # It creates a hidden .git folder tracking changes. Your folder has now a local repo.Check Status: Use below command to show modified, staged, or untracked files:
git status # It shows modified, staged, or untracked filesStage and Commit Changes: Create/edit files, then :
git add filename.txt # Stage one file git add . # Stage all git commit -m "Initial commit"The message describes the snapshot.
View History:
git log --oneline #Lists commits with short IDs and commit messagesUndo Changes: Cover safe recovery with
git restorefor unstaged edits,git resetfor unstaged commits (with caution), andgit revertfor committed changes. Emphasize checkinggit statusfirst to avoid mistakes.git restore filename.txt # Discard edits git checkout -- filename.txt # Alternative #safe for unstaged files.
Save snapshot to remote repo: Connect to a remote repo like GitHub/GitLab via git remote add origin, git push to upload, and git pull/git fetch to sync. But for that to work, you definitely need to first create an account and perform first push.
git push origin main # publishing latest snapshot from local repo to remote repo
git pull # get the local repo in sync with remote repo
Summary of most common git commands based on their use case:
| Workflow | Key Commands | Use Case |
| First Commit | git init, git add ., git commit | New project setup |
| Daily Changes | git status, git add, git commit | Track edits |
| Branch & Merge | git checkout -b feature, git merge | Test features safely |
| Remote Sync | git push origin main, git pull | Share with team |
Developer Workflow
In the below illustration, I am giving a step-by-step example to give you an idea on a common workflow that a developer has to go through in his/her day-to-day software development work. However, there are many other corrective steps and actions that are used in cases of fixing wrong/corrupted project snapshots or mapping the snapshots to relevant branches. That are not topic of basics understanding, hence out of scope for this blog.
# 1. Create project folder
mkdir my-app
cd my-app
# 2. Initialize Git
git init
# 3. Create a file
echo "Hello Git" > app.txt
# 4. Check status
git status
# 5. Stage file
git add app.txt
# 6. Commit
git commit -m "Initial commit"
# 7. View history
git log
What Just Happened?
Git started tracking your project
File was staged and committed
History is now preserved forever
What is Next?
Now let’s understand the developers workflow with git, how git works at local level as well as at the remote repository of single source of truth. In order to do so, let us refer the below flow diagram:

The above diagram shows a typical modern Git + GitHub/GitLab/BitBucket workflow from local development to CI/CD and deployment. Each step both structures the work and protects quality.
Step 1–2: Sync and Create a Feature Branch
git pull origin main(update local main) – The developer first synchronizes the local main branch with the remote repository to ensure they build on the latest code, reducing later merge conflicts.git checkout -b feature-branch(create & switch to branch) – A dedicated branch isolates the new feature or bug fix, keeping the main branch clean and deployable at all times.
How this helps:
Conflicts are minimized because everyone branches from a common, up‑to‑date base.
main remains stable, which supports trunk‑based development, GitHub Flow, or Git-flow style workflows.
Step 3–5: Develop, Stage, and Commit Locally
Develop code & run local tests – Work happens entirely on the local clone; developers can iterate, refactor, and run tests offline without impacting others.
git add <files>(stage changes) – Staging lets developers build a precise set of changes into each commit, grouping related edits together.git commit -m "message"(commit changes) – Each commit records a snapshot plus a descriptive message, creating a clear, review-able history for future debugging and auditing.
How this helps:
Local commits are fast and independent of network latency.
Fine‑grained commits with good messages make code review and rollback straightforward.
Step 6: Push Branch to Remote
git push origin feature-branch(push branch to remote) – The feature branch is uploaded to GitHub/GitLab/BitBucket so others can review and CI pipelines can run.
How this helps:
Work becomes shareable and visible to teammates.
CI systems connected to the remote repo can automatically build and test the branch.
Step 7–8: Open Pull Request and Run Review + CI
- Create Pull Request (PR) against
main– On the platform, the developer opens a PR (GitHub), merge request (GitLab), or similar in BitBucket, requesting that the feature branch be merged into main.
8a. Peer code review (approve/request changes) – Reviewers inspect the diff, comment on lines, suggest changes, and either approve or request revisions.
8b. Automated CI pipeline (build, lint, test) – CI runs the configured jobs (unit tests, integration tests, linters, security scans) on the branch and reports status back to the PR.
How this helps:
PRs formalize peer review, improving code quality and knowledge sharing, especially for junior developers.
Automated CI catches regressions early and blocks merges when tests fail, enforcing quality gates consistently.
Step 8 Decision: PR Approved & CI Passed?
“PR Approved & CI Passed?” – If reviewers request changes or CI fails, the developer returns to step 3, updates the code on the same branch, and pushes again; the PR and CI rerun automatically.
How this helps:
Encourages iterative improvement until code quality and test coverage meet the team’s standards.
Keeps broken code from ever reaching main, which stabilizes releases.
Step 9–10: Merge and Deploy via CD
Merge PR to
mainbranch – Once approved and green, the platform merges the feature branch into main (often using squash or rebase strategies to keep history clean).Automated CD pipeline (deploy to staging/production) – A CD pipeline triggers on changes to main, deploying to staging and/or production environments as configured.
How this helps:
Merges are controlled and auditable, with a clear link from commits to reviews and issues.
CD automates deployments, reducing manual errors and shortening time‑to‑production for each change.
Step 11: Sync Local After Deployment
git checkout main&git pull(sync local) – After the feature is merged and deployed, the developer switches back to main and pulls the latest state so the next feature starts from an up‑to‑date code base.
How this helps:
Ensures the developer’s local environment matches what is in production or staging.
Reduces future merge conflicts and keeps branches short‑lived, which aligns with modern Git-flow/GitHub Flow practices.
Conclusion
In this article, we got a step-by-step walk through on how to install git and also how to use git for tracking our software projects, to make software development journey easier and organized. The below diagram is the concept summary of git workspace stages and what actions are commonly performed at each stage

If you liked my article, you can subscribe to my blog and get notified, whenever I write a new article on other topics relating to software engineering.
Namaste! Jai Hind!